From Noise to Data: A Field Guide to Diffusion and Flow Models
Diffusion and flow matching are two parameterizations of one continuous-time object — the probability-flow ODE. A ground-up review, an annotated timeline, and the current open-weights landscape.
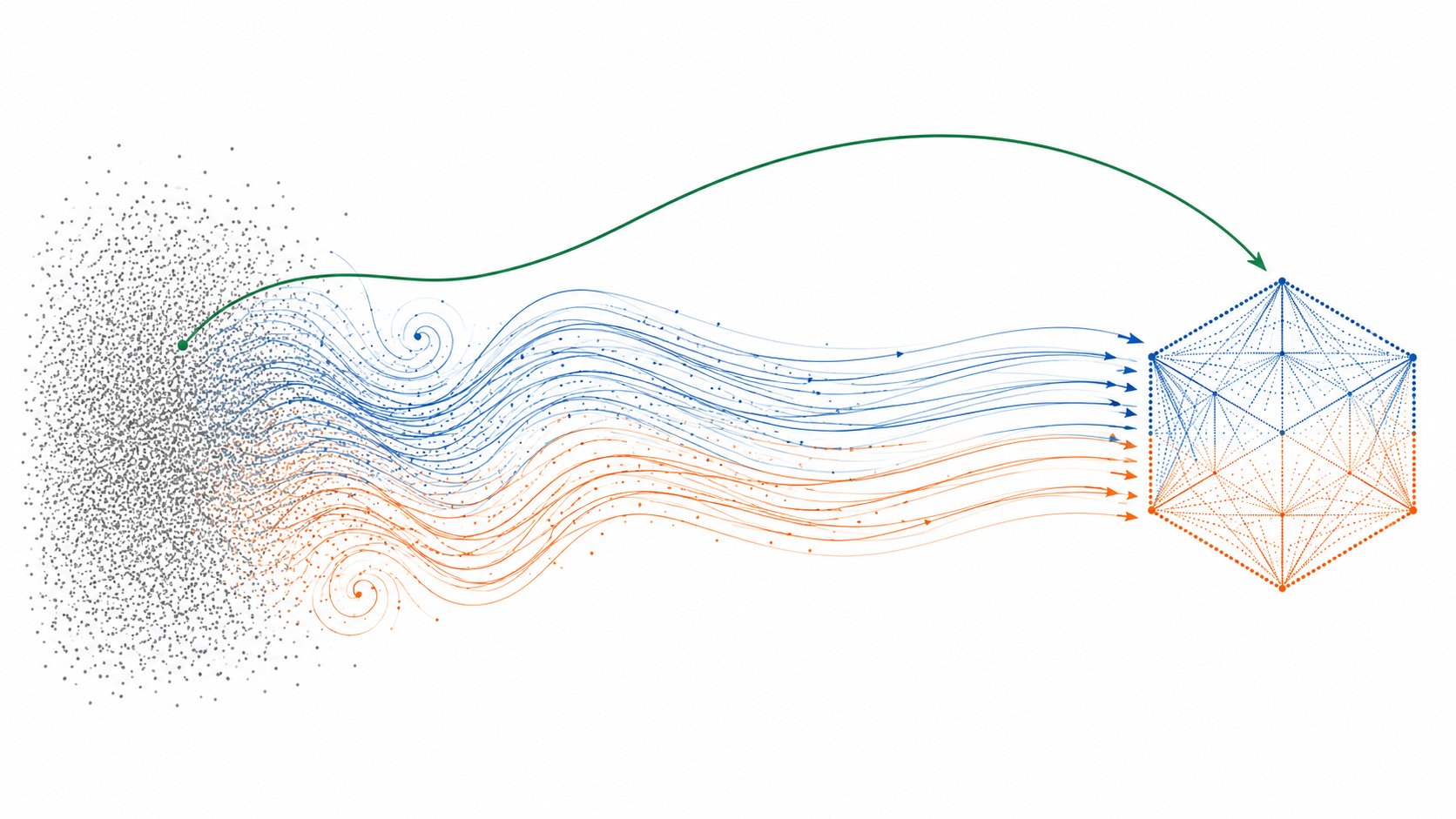
Modern image and video generators almost all share one idea: learn a time-dependent vector field that transports simple noise into data, then integrate it. Diffusion gets at that field indirectly, through a score or noise predictor; flow matching regresses it directly as a velocity — but underneath, both integrate the same probability-flow ODE. What genuinely separates them is practical: path choice, training objective, discretization, solver, engineering details. This review builds that picture from the ground up, then traces how the field arrived there and what the current open-weights landscape looks like.
TL;DR — five takeaways
- Diffusion and flow matching are two parameterizations of one continuous-time object — the probability-flow ODE. Given the same marginal path, learning the score and learning the velocity are two views of the same transport; the algorithms still differ in paths, losses, and solvers (§1.2–1.3).
- The production recipe has converged: straight rectified-flow paths + a multi-stream Diffusion Transformer (MMDiT) + an increasingly LLM-grade text encoder, trained as plain velocity regression (§1.4, §2.3).
- Fast sampling moved from solving the ODE better to learning its integral. Training-free solvers bottom out around 10–20 steps; the newer flow-map family — descendants of consistency models — reaches 1–4-step quality trained from scratch, with no distillation (§1.7, §2.4).
- The field is rerunning the LLM playbook — Transformer backbones with compute-predictable scaling, MoE, text encoders replaced by LLMs — with one deep difference: the core object is continuous transport, not discrete autoregression.
- Open weights are no longer toy baselines. Recent open image and video models reach tens of billions of parameters and increasingly use the same flow / DiT / MoE recipes thought to power closed systems (Part III).
If you’re coming from LLMs, here is the translation key. The VAE latent space plays the role of the tokenizer; DiT was this field’s “just use a Transformer” moment, with the same compute-predictable scaling curves; MoE arrived in 2025 (HiDream-I1’s sparse DiT in image, Wan 2.2’s high-/low-noise experts in video); prompt understanding has been outsourced to actual LLMs and VLMs (CLIP/T5 → Qwen, Mistral-3); and the entire few-step program of §1.7 is this field’s version of the inference-cost stack (distillation, quantization, speculative decoding). The one fundamental difference — autoregressive factorization over discrete tokens versus continuous-time transport — is itself eroding from both ends; see the Outlook.
How to read this. Part I is conceptual and self-contained: it builds the core model, shows the diffusion/flow correspondence early, then branches into the practical axes (path choice, parameterization, guidance, fast sampling). Part II is a lean annotated timeline that points back to Part I rather than re-deriving anything. Part III surveys open models. The appendix gives full derivations. For background reading in roughly this order:
- Lilian Weng — What are Diffusion Models? — concrete DDPM-first build-up.
- Yang Song — Score-Based Generative Modeling — the continuous-time / SDE view.
- Albergo–Boffi–Vanden-Eijnden — Stochastic Interpolants — top-down unification via a single interpolant.
- Diffusion Meets Flow Matching — shows explicitly how the two map onto the same model under different parameterizations.
- Lipman et al. — Flow Matching Guide and Code (2024) — standard reference + implementation.
Notation and conventions
One convention is used everywhere below; it is worth fixing in mind before reading.
| Symbol | Meaning |
|---|---|
| \(x_0\) | a clean data sample, \(x_0\sim p_{\text{data}}\) |
| \(\varepsilon\) | noise, \(\varepsilon\sim\mathcal N(0,I)\) |
| \(t\) | time, \(t=0\) is data, increasing \(t\) is more noise (continuous \(t\in[0,1]\), or discrete \(1,\dots,T\)) |
| \(x_t\) | the partially-noised state at time \(t\) |
| \(\bar\alpha_t,\ \alpha_t,\ \sigma_t\) | noise-schedule coefficients; \(x_t=\sqrt{\bar\alpha_t}\,x_0+\sqrt{1-\bar\alpha_t}\,\varepsilon\) |
| \(\varepsilon_\theta,\ s_\theta,\ v_\theta\) | the network as a noise predictor, score estimator, or velocity field |
| \(w\) | classifier-free guidance scale |
Sampling always means starting from noise (large \(t\)) and moving toward data (\(t\to0\)) — i.e. integrating the dynamics in the direction of decreasing \(t\). The flow-matching literature usually flips this (puts data at \(t=1\) and noise at \(t=0\), velocity pointing noise→data); the two differ only by relabeling, and the flip is flagged wherever it would otherwise cause confusion.
Part I — Concepts: one framework, built up
1.1 The shared setup: corrupting data along a path
Every model here starts by defining a path that interpolates between a data sample and pure noise. In the Gaussian case this is
\[x_t = \sqrt{\bar\alpha_t}\,x_0 + \sqrt{1-\bar\alpha_t}\,\varepsilon,\qquad \varepsilon\sim\mathcal N(0,I),\]so \(x_t\approx x_0\) near \(t=0\) and \(x_t\approx\varepsilon\) near \(t=1\). DDPM (Ho et al., 2020) realizes this as a Markov chain \(q(x_t\mid x_{t-1})=\mathcal N(\sqrt{1-\beta_t}\,x_{t-1},\beta_t I)\) whose accumulated effect is exactly the closed form above with \(\alpha_t=1-\beta_t\), \(\bar\alpha_t=\prod_{s\le t}\alpha_s\). The continuous-time view (next section) treats the same corruption as an SDE. The flow-matching view treats it as a chosen interpolant. These are three descriptions of one path — keep that in mind; it is the whole point.
The generative task is to reverse the path: given a sample of noise, walk back to a plausible data sample. There are two equivalent ways to learn how.
1.2 Reversing it, view A — score, SDE, and the probability-flow ODE
Song et al. (2021) cast the corruption as a forward SDE \(dx=f(x,t)\,dt+g(t)\,dw\). The reverse process needs only the score of the time-marginals, \(\nabla_x\log p_t(x)\), and admits both a stochastic and a deterministic form sharing the same marginals:
\[\underbrace{dx=\big[f-g^2\nabla_x\log p_t\big]dt+g\,d\bar w}_{\text{reverse SDE}} \qquad \underbrace{dx=\big[f-\tfrac12 g^2\nabla_x\log p_t\big]dt}_{\textbf{probability-flow ODE}}.\]The score is learned by denoising score matching, which for the Gaussian path is just noise prediction up to a scale — the score model is parameterized as (derivation in A.2):
\[s_\theta(x_t,t)=-\,\frac{\varepsilon_\theta(x_t,t)}{\sqrt{1-\bar\alpha_t}}\ \approx\ \nabla_x\log p_t(x_t) .\]The key object to carry forward is the probability-flow (PF) ODE: a deterministic trajectory whose drift is a velocity field. Solving it instead of the SDE is what enables fast, deterministic, few-step sampling.
1.3 Reversing it, view B — velocity, and why it is the same ODE
Flow matching (Lipman et al., 2022) skips the stochastic framing and learns the ODE’s velocity field directly. Pick a path \(p_t\) from noise to data; a velocity \(u_t(x)\) generates it iff it satisfies the continuity equation, and samples follow \(\dot x=u_t(x)\):
\[\partial_t p_t + \nabla\!\cdot(p_t\,u_t)=0,\qquad \dot x=u_t(x).\]Here is the unification. Apply the Fokker–Planck equation to the forward SDE and fold the diffusion term into the drift (full steps in A.3):
\[\partial_t p_t = -\nabla\!\cdot\!\Big[\big(\underbrace{f-\tfrac12 g^2\nabla\log p_t}_{\text{PF-ODE drift}}\big)p_t\Big].\]That is the continuity equation with velocity equal to the PF-ODE drift. So, given the same time-marginal path \(p_t\), the PF-ODE of a diffusion process is a velocity field satisfying exactly the continuity equation flow matching starts from. At the continuous-time marginal level, the two learn views of one transport: diffusion builds the velocity from a learned score, flow matching regresses it directly. They are not identical as algorithms — conditional paths, losses, discretizations, solvers, and parameterizations can all differ, and those choices matter in practice. What they share is the underlying object.
 Figure 1 — The score/noise view and the velocity view meet at the same continuity equation, at the level of continuous-time marginals; as algorithms they still differ in paths, losses, and solvers. §1.5 explains how the \(\varepsilon\) / score / velocity output heads convert into one another; few-step methods (§1.7) then learn the integral of \(u\) rather than \(u\) itself.
Figure 1 — The score/noise view and the velocity view meet at the same continuity equation, at the level of continuous-time marginals; as algorithms they still differ in paths, losses, and solvers. §1.5 explains how the \(\varepsilon\) / score / velocity output heads convert into one another; few-step methods (§1.7) then learn the integral of \(u\) rather than \(u\) itself.
Why regress directly? Because it can be made simulation-free. The true marginal velocity is intractable, but conditioning on a data sample gives a closed-form target, and the Conditional Flow Matching loss has the same gradient as the intractable marginal loss (proof in A.4):
\[\mathcal L_{\text{CFM}}=\mathbb E_{t,\,x_0,\,x_t\sim p_t(\cdot\mid x_0)}\big\|v_\theta(x_t,t)-u_t(x_t\mid x_0)\big\|^2,\qquad \nabla_\theta\mathcal L_{\text{FM}}=\nabla_\theta\mathcal L_{\text{CFM}} .\]So you sample a data point, sample a point on its conditional path, and regress on a closed-form velocity — never simulating the full process.
| View A — diffusion | View B — flow matching | |
|---|---|---|
| Learned target | noise \(\varepsilon\) / score \(\nabla\log p_t\) | velocity \(v(x,t)\) |
| Dynamics | reverse SDE or PF-ODE | ODE \(\dot x=v(x,t)\) |
| Path | fixed by the \(\beta\)-schedule | chosen freely (VP, OT/linear, …) |
| Training | denoising / score matching | conditional velocity regression |
| Typical steps | 20–1000 (SDE), 10–50 (ODE) | 20–50 (Euler); 1–4 after reflow / flow maps (§1.7) |
1.4 Choosing the path: rectified flow
Once you can pick the path, the obvious choice is the straight line — Rectified Flow (Liu, Gong, Liu, 2022). In our convention (\(x_0\) data, \(\varepsilon\) noise, \(t=0\)→data):
\[x_t=(1-t)\,x_0+t\,\varepsilon,\qquad \frac{dx_t}{dt}=\varepsilon-x_0\ \ (\text{constant}),\]so the conditional velocity is constant and training is a plain regression \(\mathcal L=\mathbb E\,\|v_\theta(x_t,t)-(\varepsilon-x_0)\|^2\). (The original paper uses the reverse time direction, \(x_t=(1-t)\varepsilon+t\,x_0\); same line, opposite labels.) Straight paths mean Euler integration with very few steps is already accurate, and reflow re-couples \((x_0,\varepsilon)\) pairs along the learned ODE to straighten further. This linear-path recipe is exactly what SD3, FLUX, Qwen-Image, and Wan scaled up.
 Figure 2 — Training-time geometry: many conditional paths share the same endpoints, and their curvature is a modeling choice. Rectified flow picks the straight one — and reflow re-learns couplings toward it — which is what lets coarse Euler integration stay accurate.
Figure 2 — Training-time geometry: many conditional paths share the same endpoints, and their curvature is a modeling choice. Rectified flow picks the straight one — and reflow re-learns couplings toward it — which is what lets coarse Euler integration stay accurate.
 Figure 3 — Sampling-time consequence: one transport, four traversals. Stochastic reverse SDE; the deterministic PF-ODE with a high-order solver; near-straight rectified flow, where a handful of Euler steps suffice; and a flow map (§1.7), which skips integration entirely. Straighter trajectories tolerate coarser integration — that single geometric fact drives most of the speed story.
Figure 3 — Sampling-time consequence: one transport, four traversals. Stochastic reverse SDE; the deterministic PF-ODE with a high-order solver; near-straight rectified flow, where a handful of Euler steps suffice; and a flow map (§1.7), which skips integration entirely. Straighter trajectories tolerate coarser integration — that single geometric fact drives most of the speed story.
1.5 One network, three targets: \(\varepsilon\) / \(x_0\) / \(v\)
The same network can output the noise \(\varepsilon\), the clean sample \(x_0\), or the velocity \(v\) (Salimans & Ho, 2022):
\[v\ \equiv\ \sqrt{\bar\alpha_t}\,\varepsilon-\sqrt{1-\bar\alpha_t}\,x_0 .\]These are linearly interchangeable (given \(x_t\), any one determines the others), but they weight the loss differently across noise levels, which matters for stability at high resolution. Crucially, \(v\) is the flow-matching velocity for the corresponding Gaussian path, up to a schedule-dependent rescaling of time (see A.5) — which is why modern flow models simply train \(v_\theta\).
1.6 Steering the field: classifier-free guidance
Conditioning (text, class, layout) is injected into the backbone via cross-attention (joint text–image attention in MMDiT-style backbones, adaLN for class labels), and controllability comes almost entirely from classifier-free guidance (Ho & Salimans, 2022). Train one model jointly on conditional \(c\) and a null token \(\varnothing\) (random condition dropout), then at sampling time extrapolate along the conditional direction:
\[\tilde v_\theta(x_t,c)=v_\theta(x_t,\varnothing)+(w+1)\big(v_\theta(x_t,c)-v_\theta(x_t,\varnothing)\big),\]with the identical formula for \(\varepsilon_\theta\). Larger \(w\) buys prompt adherence at the cost of diversity and can over-saturate; much recent work schedules or corrects \(w\) to mitigate this. (Codebases often write \(\tilde v=v(\varnothing)+s\,(v(c)-v(\varnothing))\) with \(s=w+1\), e.g. \(s\approx7.5\).)
1.7 Collapsing the steps: distillation → consistency → flow maps → mean flows
The remaining bottleneck is that integrating the ODE still takes many steps. Three lineages attack this at training time, and 2024–2026 has seen them converge on a single idea — a network conditioned on two times that learns the jump between them.
- Distillation. Progressive Distillation (Salimans & Ho, 2022) and later adversarial/variational variants compress a many-step teacher into a few-step student.
- Consistency models (Song et al., 2023) learn a map sending any point on a PF-ODE trajectory straight to its origin; its continuous-time form was stabilized and scaled by sCM / TrigFlow (Lu & Song, 2025).
- Flow maps / mean flows. Instead of the instantaneous velocity, learn the average velocity over an interval (MeanFlow, Geng et al., 2025). With \(\dot z_\tau=v(z_\tau,\tau)\),
(derivation in A.6). A single network evaluation then jumps noise→data, \(x_0=x_{\text{noise}}-u_\theta(x_{\text{noise}},0,1)\), with no teacher or distillation. The closely related shortcut models (Frans et al., 2025) condition on step size to support 1-step and multi-step in one model, and Inductive Moment Matching (Zhou et al., 2025) adds distribution-level convergence guarantees. These are all instances of a two-time-conditioned “flow map.” §2.4 covers the current state of this very active area.
 Figure 4 — Two ways across the same river. Multi-step sampling takes many small steps of the instantaneous velocity \(v(x,t)\); a flow map \(u_\theta(x,r,t)\) learns the span itself and crosses in one evaluation.
Figure 4 — Two ways across the same river. Multi-step sampling takes many small steps of the instantaneous velocity \(v(x,t)\); a flow map \(u_\theta(x,r,t)\) learns the span itself and crosses in one evaluation.
Part II — How the field got here (annotated timeline)
This part is chronological and deliberately terse; the math lives in Part I and the appendix.
2.1 Foundations (2020)
- DDPM — Ho et al., 2020 — noise→data via a learned reverse Markov chain; source of the simplified denoising objective.
- Score SDEs + probability-flow ODE — Song et al., 2021 (ICLR) — the continuous-time view that ties score, noise, and velocity together. The hinge the whole field swings on.
2.2 Building blocks (2022–2023)
Conditioning. Classifier-Free Guidance (Ho & Salimans, 2022) plus cross-attention conditioning from Imagen (Saharia et al., 2022) and Stable Diffusion / Latent Diffusion (Rombach et al., 2022).
Architecture. U-Net → Transformer → multi-stream Transformer:
- Latent Diffusion — Rombach et al., 2022 (CVPR) — diffuse in a compressed VAE latent; now near-universal.
- DiT — Peebles & Xie, ICCV 2023 (oral) — replaces the U-Net with a ViT; sample quality (FID) drops predictably as model compute (Gflops) rises, the LLM-style scaling intuition for generation.
- PixArt-α — Chen et al., arXiv 2023 (ICLR 2024) — first large open DiT-based T2I.
- MMDiT — introduced with SD3 (Esser et al., 2024) — separate text/image token streams interacting through joint attention; the dominant backbone for SD3.x, FLUX, Qwen-Image, Wan.
Training-free fast sampling (ODE solvers). DPM-Solver (Lu et al., NeurIPS 2022), DPM-Solver++, DEIS (Zhang & Chen, ICLR 2023), UniPC (Zhao et al., NeurIPS 2023) — together these cut ~1000 steps to ~20.
Training-based fast sampling. Progressive Distillation (Salimans & Ho, 2022); Consistency Models (Song et al., ICML 2023).
2.3 The flow turn (2022–2024)
- Flow Matching for Generative Modeling — Lipman et al., arXiv 2022 / ICLR 2023 — simulation-free velocity regression; diffusion paths shown to be a special case.
- Rectified Flow: Flow Straight and Fast — Liu, Gong, Liu, arXiv 2022 / ICLR 2023 — straight-line transport + reflow.
- Scaling Rectified Flow Transformers (SD3) — Esser et al., ICML 2024 — RF + MMDiT at scale; predictable scaling and strong 1024px T2I. The first SOTA-scale proof that RF + Transformer scales like diffusion with fewer steps.
- Flow Matching Guide and Code — Lipman et al., 2024 — the consolidated reference + baseline implementation.
2.4 The few-step frontier (2025–2026)
As of mid-2026, few-step generation is one of the main frontiers. The common direction is no longer only to design better ODE solvers, but to train networks that learn longer jumps of the same flow — the two-time flow-map idea of §1.7.
 Figure 5 — Solvers integrate the velocity better (and plateau); distillation compresses a teacher; the from-scratch line learns the jump itself. The last two increasingly converge on one recipe: a single network conditioned on two times.
Figure 5 — Solvers integrate the velocity better (and plateau); distillation compresses a teacher; the from-scratch line learns the jump itself. The last two increasingly converge on one recipe: a single network conditioned on two times.
Headline results, all trained from scratch without distillation unless noted:
- sCM / TrigFlow — Lu & Song, ICLR 2025 — stabilizes the continuous-time consistency objective and scales it to 1.5B params; 2-step FID ≈ 1.88 on ImageNet 512×512, i.e. diffusion-quality at roughly one-tenth the sampling compute.
- Inductive Moment Matching (IMM) — Zhou, Ermon, Song, ICML 2025 — single-stage training with distribution-level convergence guarantees (unlike consistency models); 1.99 FID at 8 steps on ImageNet 256, strong 1–2 step results.
- MeanFlow — Geng, Deng, Bai, Kolter, He, NeurIPS 2025 (oral) — average-velocity field enabling true one-step generation; 1-NFE FID 3.43 on ImageNet 256, no distillation/curriculum. Follow-ups: Improved MeanFlow (Geng et al., Dec 2025), Modular/Split MeanFlow, and unifying analyses (AlphaFlow) showing mean flows, shortcut, and consistency are interpolations of one objective.
- Shortcut models — Frans, Hafner, Levine, Abbeel, ICLR 2025 — step-size-conditioned net, 1-step and multi-step in one model, no separate distillation.
- Terminal Velocity Matching (TVM) — ICLR 2026 — generalizes MeanFlow by modeling the transition between any two timesteps with a regularization at the terminal time, and proves a 2-Wasserstein bound under Lipschitz continuity. 1-NFE FID 3.29 / 4-NFE 1.99 on ImageNet 256 (the 4-NFE number already beats DiT’s 2.27 multi-step baseline), and 4.32 / 2.94 on ImageNet 512; the paper also diagnoses (and fixes) a Lipschitz-continuity gap in standard DiT backbones, and reports text-to-image results at 10B+ scale (company blog).
- Drifting models — Deng, Li, Li, Du, He, 2026 — a further “generative modeling via drifting” formulation in the same flow-map family.
The practical upshot: as of 2026 one- to four-step generators are competitive with many-step diffusion on standard benchmarks without GAN-style adversarial training, and the recipes are converging on a single two-time-conditioned network. The model-level consequences — who ships what, at what scale, under which license — are surveyed in Part III.
Part III — The open-weights landscape
This section is a snapshot of the open-weights landscape rather than a fixed benchmark table. Model names, checkpoint availability, licenses, and reported numbers change quickly; the tables list claims that are easy to trace to papers, official repositories, or model cards, and anything time-sensitive should be re-checked there — including the license, before any commercial use.
Three trends frame the tables below. Scale: open text-to-image jumped roughly an order of magnitude in about a year — from the ~2–3B SDXL era to 20B-class (Qwen-Image) and 32B-class (FLUX.2) flow-matching Transformers, with distilled variants bringing sub-second generation to consumer GPUs. Text encoders: LLM/VLM-grade encoders are replacing CLIP/T5 for prompt understanding. Video: open video models increasingly combine DiT/flow objectives with MoE, efficient attention, and stronger video VAEs — Wan 2.2’s two-expert design (a high-noise expert for layout, a low-noise expert for detail) is the clearest example. The closed systems that still own the quality peak are surveyed separately in §3.3.
3.1 Image (text-to-image, often + editing)
| Model | Backbone / objective | What’s open | Notable |
|---|---|---|---|
| FLUX.2 (pro / flex / dev / klein) — BFL, Nov 2025; klein Jan 2026 | 32B flow-matching Transformer; Mistral-3 24B VLM text encoder | dev 32B weights + code (FLUX non-commercial); klein 4B Apache-2.0 / 9B non-commercial; VAE Apache-2.0 | Multi-reference (~10 imgs), 4MP editing, strong typography; klein gives sub-second generation |
| HunyuanImage 3.0 (+ Instruct) — Tencent, Sep 2025 / Jan 2026 | ~80B MoE (~13B active), unified autoregressive | Weights + code, Hunyuan Community License | Largest open T2I; Instruct adds a reasoning pass |
| Qwen-Image (+ Edit, + 2512) — Alibaba, Aug & Dec 2025 | ~20B MMDiT, rectified flow; 8.29B text encoder | Weights + code, Apache-2.0 | Best open text rendering (incl. Chinese); “Lightning” few-step. (Qwen-Image-2.0, Feb 2026, is API-only) |
| Cosmos 3 (Nano 16B / Super 64B) — NVIDIA, ~May 2026 | Omnimodal mixture-of-transformers, two-tower; T2I is one mode | Weights, OpenMDW-1.1 | Reported top of the open T2I arena; physical-AI foundation model |
| ERNIE Image — Baidu, Apr 2026 | 8B single-stream DiT | Weights + code, Apache-2.0 | Fully permissive; runs on a single 24 GB GPU |
| HiDream-O1 — HiDream.ai, May 2026 | 8B pixel-native unified transformer (no VAE) | Weights, MIT | Reasoning-driven prompt agent; successor to HiDream-I1 |
| Stable Diffusion 3.5 (L / M / Turbo) — Stability, 2024 | MMDiT, rectified flow; CLIP-L + OpenCLIP bigG + T5-XXL, 16-ch VAE | Weights + code (Stability Community License) | Open ControlNets; Turbo for few-step |
| Sana — NVIDIA, 2024–2025 | Linear-attention DiT, deep-compression VAE | Weights + code | Very fast high-res (to 4K) on modest hardware |
| Unified gen + understanding — BAGEL (ByteDance), Janus-Pro (DeepSeek), OmniGen2 | any-to-any; a generation head folded into an understanding model | Weights + code (Apache-2.0 / MIT) | The open unified-model class; strong GenEval at small scale |
| Ideogram 4.0 — Ideogram, Jun 2026 | 9.3B DiT | Weights (research-only license — not commercial) | Tops DesignArena; typography / layout |
| SDXL — 2023 | U-Net, ε-pred | Weights + code (community) | ~3.5B; the canonical baseline + huge LoRA/ControlNet ecosystem |
Also open and current: CogView4 (Zhipu, Apache-2.0, native-Chinese text), Lumina-Image 2.0 (Alpha-VLLM). Legacy / historically important: PixArt-Σ/α, Playground v2.5, Kolors, DeepFloyd IF, SSD-1B.
3.2 Video (T2V / I2V / S2V)
| Model | Backbone / objective | What’s open | Notable |
|---|---|---|---|
| Wan 2.2 (+ Animate) — Alibaba, Jul 2025 | MoE flow-matching DiT (high-/low-noise experts; ~27B total, ~14B active per step) | Weights + code, Apache-2.0 | Open VBench leader; 5B variant on consumer GPUs; S2V; Wan2.2-Animate (Sep 2025) adds character animation. Wan 2.5 / 2.6 / 2.7 are API-only — no open weights |
| LTX-2 — Lightricks, Jan 2026 | DiT, joint audio + video | Weights + code (open) | First production-ready open model with synchronized 4K audio+video, up to ~20 s / 50 fps |
| HunyuanVideo 1.5 — Tencent, Nov 2025 | DiT, flow matching + 3D causal VAE | Weights + code, Tencent Hunyuan Community License (excludes EU / UK / South Korea) | 8.3B, runs on a single 4090; SOTA-among-open at launch; official I2V |
| SkyReels-V3 — Skywork, Jan 2026 | DiT | Weights + code | Multimodal (A2V / R2V / V2V); long-/infinite-length lineage from V2 |
| Open-Sora 2.0 — HPC-AI Tech, Mar 2025 | STDiT + compressive 3D VAE | Full pipeline + weights | Fully open recipe; VBench gap to Sora narrowed to ~0.7% |
| CogVideoX / 1.5 (+ I2V) — Zhipu | DiT | Weights + code | Open 5B series; ~10-s clips |
| Mochi 1 — Genmo | Asymmetric DiT | Weights + code, Apache-2.0 | ~10B; strong motion / prompt adherence |
| Step-Video-TI2V — StepFun | 30B DiT | Paper + code + weights | Up to ~102 frames; strong text-driven I2V |
Legacy: Stable Video Diffusion (Stability, 2023 — the long-standing SD2.x-generation I2V baseline) and AnimateDiff (2023 — an SD-1.5 plug-in motion module, since superseded for character animation by Wan2.2-Animate).
3.3 The closed frontier (for calibration)
The quality peak still sits behind closed APIs, and those systems disclose capabilities, not recipes — so they belong here only as calibration. Almost everything below is inferred (latent diffusion / flow matching + a DiT/transformer backbone, a 3D-VAE for video, increasingly joint audio); the two genuine architectural disclosures are flagged.
Image. OpenAI GPT Image (the GPT-4o-class system; GPT Image 2, Apr 2026) is the one disclosed outlier — an autoregressive token model rather than diffusion, with a reasoning pass. Google Nano Banana Pro (= Gemini 3 Pro Image, Nov 2025) is Gemini-native. FLUX.2 [pro] is the closed tier of the otherwise-open FLUX.2 flow-matching DiT. ByteDance Seedream 4.5, Midjourney V7 (V8 in alpha), and Ideogram / Reve / Recraft / Adobe Firefly round out the commercial tier.
Video. ByteDance Seedance 2.0 and Kuaishou Kling 3.0 currently top the audio-enabled arenas; Google Veo 3.1 (native synchronized audio) leads the Western models; OpenAI Sora 2 was a 2025 frontier model, though the Sora product is being wound down through 2026. Runway Gen-4.x, MiniMax Hailuo, Luma Ray3, and Pika fill the next tier.
The gap, mid-2026. Narrowed sharply but not closed at the peak. In video, open weights (Wan 2.2, HunyuanVideo 1.5, LTX-2) post VBench-class scores within a few points of the closed leaders — a genuine production option — while Veo / Kling / Seedance still lead on average quality, audio, and long-horizon coherence. In image, FLUX.2-dev and Qwen-Image are competitive on visual semantics and layout but trail GPT Image and Gemini 3 Pro Image on the hardest reasoning-heavy and dense-text prompts. Net: closed owns the frontier peak, while open weights have reached the prior generation’s frontier at far lower cost.
Outlook — open problems
A review should end with a position, so here is where this appears to be heading and what is genuinely unsolved.
-
Flow maps become the default training recipe. The bet: two-time objectives (MeanFlow / TVM-style) displace the train-then-distill pipeline for production models — TVM already beats the DiT multi-step baseline at 4 NFE on ImageNet, and its developers report text-to-image results at 10B+ scale. The open issues are training cost and stability: JVP-based objectives stress standard DiT backbones enough that TVM had to add normalization to restore Lipschitz behavior, hinting that few-step training may end up reshaping the architecture itself.
-
Guidance is still a hack. CFG doubles inference cost and samples from a tilted distribution rather than the true conditional; schedulers, guidance distillation, and autoguidance are patches, not fixes. The problem sharpens as NFE → 1 — with no trajectory left to steer, guidance must be folded into the learned field itself, the route Improved MeanFlow takes by treating the guidance scale as an explicit conditioning variable. A principled theory of conditioning strength remains open.
-
Continuous and discrete generation are invading each other. Next-scale autoregression (the VAR line) attacks images with the LLM recipe while diffusion language models attack text with the transport recipe, and unified multimodal models will eventually force a common interface. Whichever side first matches the other’s quality–cost frontier at scale decides more than any single benchmark.
-
Evaluation is breaking. ImageNet FID is saturated and increasingly uninformative at frontier scale, so the field is drifting to human-preference Elo arenas — which are noisy, expensive, and gameable. A trustworthy automated metric for frontier-quality generation is an unsolved, high-leverage problem.
-
Video wants state. Current models generate seconds at a time; long-horizon consistency of identity, physics, and scene state is the gap between clip generators and world models. MoE + flow matching addressed compute — memory is the next bottleneck.
Cheat sheet
| Concept | Core relation |
|---|---|
| Gaussian path | \(x_t=\sqrt{\bar\alpha_t}\,x_0+\sqrt{1-\bar\alpha_t}\,\varepsilon\) |
| DDPM loss | \(\mathbb E\,|\varepsilon-\varepsilon_\theta(x_t,t)|^2\) |
| Probability-flow ODE | \(dx=[\,f-\tfrac12 g^2\nabla_x\log p_t\,]\,dt\) |
| Score ↔ noise | \(s_\theta=-\,\varepsilon_\theta/\sqrt{1-\bar\alpha_t}\approx\nabla_x\log p_t(x_t)\) |
| Conditional flow matching | \(\mathbb E\,|v_\theta(x_t,t)-u_t(x_t\mid x_0)|^2\) |
| Rectified-flow target | \(v_\theta(x_t,t)\to(\varepsilon-x_0)\), with \(x_t=(1-t)x_0+t\varepsilon\) |
| \(v\)-prediction | \(v=\sqrt{\bar\alpha_t}\,\varepsilon-\sqrt{1-\bar\alpha_t}\,x_0\) |
| Classifier-free guidance | \(\tilde v=v(\varnothing)+(w+1)\,[\,v(c)-v(\varnothing)\,]\) |
| MeanFlow identity | \(u=v-(t-r)(\partial_t u+v\,\partial_z u)\) |
Cite this post
@article{zheng2026noise,
title = "From Noise to Data: A Field Guide to Diffusion and Flow Models",
author = "Zheng, Amber Yijia",
journal = "amberyzheng.com",
year = "2026",
month = "Jun",
url = "https://www.amberyzheng.com/blog/from-noise-to-data/"
}
Appendix A — Detailed derivations
Self-contained; prerequisites are the Gaussian KL divergence and the divergence theorem. The conventions of the Notation section hold throughout: \(x_0\) is data, \(\varepsilon\) noise, \(t=0\) data.
A.1 The DDPM variational bound (ELBO) reduces to denoising
Maximize \(\log p_\theta(x_0)\) via the forward chain as a variational distribution, written as an upper bound on the negative log-likelihood:
\[-\log p_\theta(x_0)\le \mathbb E_q\!\left[-\log\frac{p_\theta(x_{0:T})}{q(x_{1:T}\mid x_0)}\right]=:L .\]Rewriting each forward step with the Bayes-flipped posterior \(q(x_{t-1}\mid x_t,x_0)\) (tractable because conditioning on \(x_0\) keeps everything Gaussian) makes \(L\) telescope:
\[L=\underbrace{D_{\mathrm{KL}}\!\big(q(x_T\mid x_0)\,\|\,p(x_T)\big)}_{L_T:\ \text{no parameters}}+\sum_{t=2}^{T}\underbrace{D_{\mathrm{KL}}\!\big(q(x_{t-1}\mid x_t,x_0)\,\|\,p_\theta(x_{t-1}\mid x_t)\big)}_{L_{t-1}:\ \text{denoising}}\underbrace{-\log p_\theta(x_0\mid x_1)}_{L_0} .\]The forward posterior is Gaussian, \(q(x_{t-1}\mid x_t,x_0)=\mathcal N(\tilde\mu_t,\tilde\beta_t I)\) with
\[\tilde\beta_t=\frac{1-\bar\alpha_{t-1}}{1-\bar\alpha_t}\beta_t,\qquad \tilde\mu_t=\frac{\sqrt{\bar\alpha_{t-1}}\,\beta_t}{1-\bar\alpha_t}\,x_0+\frac{\sqrt{\alpha_t}\,(1-\bar\alpha_{t-1})}{1-\bar\alpha_t}\,x_t .\]With \(p_\theta(x_{t-1}\mid x_t)=\mathcal N(\mu_\theta,\sigma_t^2 I)\) — here \(\sigma_t^2\) is the fixed reverse-step variance (typically \(\beta_t\) or \(\tilde\beta_t\)), not the path noise scale of A.5 — the equal-variance Gaussian KL is a scaled mean gap: \(L_{t-1}=\frac{1}{2\sigma_t^2}\|\tilde\mu_t-\mu_\theta\|^2+\text{const}\). Substituting \(x_0=\tfrac{1}{\sqrt{\bar\alpha_t}}(x_t-\sqrt{1-\bar\alpha_t}\,\varepsilon)\) collapses \(\tilde\mu_t\) to \(\tfrac{1}{\sqrt{\alpha_t}}(x_t-\tfrac{\beta_t}{\sqrt{1-\bar\alpha_t}}\varepsilon)\); choosing the same form for \(\mu_\theta\) with \(\varepsilon_\theta\) in place of \(\varepsilon\) gives
\[L_{t-1}=\frac{\beta_t^2}{2\sigma_t^2\,\alpha_t(1-\bar\alpha_t)}\,\|\varepsilon-\varepsilon_\theta(x_t,t)\|^2+\text{const}.\]Dropping the \(t\)-dependent weight yields \(\mathcal L_{\text{simple}}=\mathbb E\|\varepsilon-\varepsilon_\theta\|^2\). The ELBO fully expanded is a sum of weighted denoising regressions — “predict the noise” is the bound, not a heuristic.
A.2 Noise prediction = denoising score matching (Tweedie)
Explicit score matching against the marginal score is intractable; denoising score matching (Vincent, 2011) targets the tractable conditional score and has the same minimizer:
\[\min_\theta\ \mathbb E_{x_0,\,x_t}\big\|s_\theta(x_t,t)-\nabla_{x_t}\log q(x_t\mid x_0)\big\|^2,\qquad \nabla_{x_t}\log q(x_t\mid x_0)=-\frac{x_t-\sqrt{\bar\alpha_t}\,x_0}{1-\bar\alpha_t}=-\frac{\varepsilon}{\sqrt{1-\bar\alpha_t}} .\]Hence \(s_\theta=-\varepsilon_\theta/\sqrt{1-\bar\alpha_t}\) (the §1.2 relation), and Tweedie’s formula gives the optimal denoiser from the score, \(\mathbb E[x_0\mid x_t]=\tfrac{1}{\sqrt{\bar\alpha_t}}\big(x_t+(1-\bar\alpha_t)\nabla_{x_t}\log p_t(x_t)\big)\) — so \(\varepsilon\)-, \(x_0\)-, and score-prediction are one network.
A.3 Fokker–Planck → probability-flow ODE
The forward SDE \(dx=f\,dt+g\,dw\) evolves \(p_t\) by Fokker–Planck, \(\partial_t p_t=-\nabla\!\cdot(f p_t)+\tfrac12 g^2\Delta p_t\). Using \(\Delta p_t=\nabla\!\cdot(\nabla p_t)\) and \(\nabla p_t=p_t\nabla\log p_t\):
\[\partial_t p_t=-\nabla\!\cdot\!\Big[\big(f-\tfrac12 g^2\nabla\log p_t\big)p_t\Big].\]This is a pure continuity equation, so the deterministic ODE \(\dot x=f-\tfrac12 g^2\nabla\log p_t\) — the PF-ODE — carries the same marginals \(p_t\) as the SDE. Two consequences: the SDE and PF-ODE are interchangeable for sampling (the ODE trades stochasticity for determinism), and the PF-ODE drift is already a continuity-equation velocity — exactly the object flow matching learns.
A.4 Marginal velocity as a conditional expectation, and the CFM gradient identity
Pick conditional paths \(p_t(x\mid x_0)\) generated by known \(u_t(x\mid x_0)\), and mix over data: \(p_t(x)=\int p_t(x\mid x_0)\,p_{\text{data}}(x_0)\,dx_0\). The generating marginal velocity is the posterior-weighted average
\[u_t(x)=\int u_t(x\mid x_0)\,\frac{p_t(x\mid x_0)\,p_{\text{data}}(x_0)}{p_t(x)}\,dx_0=\mathbb E_{x_0\sim p_t(x_0\mid x)}\big[u_t(x\mid x_0)\big].\]It generates \(p_t\): differentiating the mixture and using the conditional continuity equations,
\[\partial_t p_t(x)=\int \partial_t p_t(x\mid x_0)\,p_{\text{data}}(x_0)\,dx_0=-\nabla\!\cdot\!\big(p_t(x)\,u_t(x)\big),\]since \(p_t(x)u_t(x)=\int p_t(x\mid x_0)u_t(x\mid x_0)p_{\text{data}}(x_0)\,dx_0\) by definition. \(\ \blacksquare\)
Equal gradients: expand both losses as \(\|v_\theta\|^2-2\langle v_\theta,\text{target}\rangle+\|\text{target}\|^2\). The \(\|v_\theta\|^2\) terms match (same marginal over \(x\)); the cross terms match by the tower property,
\[\mathbb E_{x\sim p_t}\langle v_\theta,u_t(x)\rangle=\mathbb E_{x\sim p_t}\big\langle v_\theta,\mathbb E_{x_0\mid x}[u_t(x\mid x_0)]\big\rangle=\mathbb E_{x_0,\,x\sim p_t(\cdot\mid x_0)}\langle v_\theta,u_t(x\mid x_0)\rangle;\]the \(\|\text{target}\|^2\) terms differ but are constant in \(\theta\). Hence \(\nabla_\theta\mathcal L_{\text{FM}}=\nabla_\theta\mathcal L_{\text{CFM}}\) — the reason flow matching is simulation-free.
A.5 Diffusion as one Gaussian flow-matching path
Take \(p_t(x\mid x_0)=\mathcal N(\alpha_t x_0,\sigma_t^2 I)\) with \(\alpha_0=1,\sigma_0=0\) (data at \(t=0\)) and increasing noise as \(t\) grows. A sample is \(x_t=\alpha_t x_0+\sigma_t\varepsilon\), and differentiating along the path gives the closed-form conditional velocity
\[u_t(x_t\mid x_0)=\dot\alpha_t x_0+\dot\sigma_t\varepsilon .\]The variance-preserving schedule (\(\alpha_t^2+\sigma_t^2=1\)) recovers DDPM and makes this velocity equal the PF-ODE drift of A.3 expressed through \(\varepsilon\) — as continuous-time objects, diffusion is flow matching on a Gaussian path (the discrete-time algorithms built on top still differ). The rectified-flow straight line is the special case \(\alpha_t=1-t,\ \sigma_t=t\), giving the constant \(u_t=\varepsilon-x_0\) of §1.4; the \(v\)-prediction target is this same velocity up to schedule-dependent scaling.
A.6 The MeanFlow identity
With instantaneous flow \(\dot z_\tau=v(z_\tau,\tau)\), define the average velocity \(u(z_t,r,t)=\frac{1}{t-r}\int_r^t v\,d\tau\), i.e. \((t-r)u=\int_r^t v\,d\tau\). Differentiating in \(t\) (the upper limit and \(z_t\) both move): the left side gives \(u+(t-r)\frac{d}{dt}u\), the right gives \(v(z_t,t)\). With the total derivative \(\frac{d}{dt}u=\partial_t u+v\,\partial_z u\),
\[u(z_t,r,t)=v(z_t,t)-(t-r)\big(\partial_t u+v\,\partial_z u\big).\]In practice the correction term is one Jacobian-vector product, and a single evaluation jumps noise→data via \(x_0=x_{\text{noise}}-u_\theta(x_{\text{noise}},0,1)\) — no teacher, no discretized timesteps.
References
Background reading and guides
- Lilian Weng — What are Diffusion Models? (2021). lilianweng.github.io
- Yang Song — Generative Modeling by Estimating Gradients of the Data Distribution (2021). yang-song.net
- Albergo, Boffi, Vanden-Eijnden — Stochastic Interpolants: A Unifying Framework for Flows and Diffusions, 2023. arXiv:2303.08797
- Diffusion Meets Flow Matching. diffusionflow.github.io
- Lipman et al. — Flow Matching Guide and Code (2024). arXiv:2412.06264
Foundations and building blocks
- Ho et al. — Denoising Diffusion Probabilistic Models (DDPM), 2020. arXiv:2006.11239
- Song et al. — Score-Based Generative Modeling through SDEs, ICLR 2021. arXiv:2011.13456
- Ho & Salimans — Classifier-Free Diffusion Guidance, 2022. arXiv:2207.12598
- Rombach et al. — High-Resolution Image Synthesis with Latent Diffusion Models, CVPR 2022. arXiv:2112.10752
- Saharia et al. — Photorealistic Text-to-Image Diffusion Models (Imagen), 2022. arXiv:2205.11487
- Peebles & Xie — Scalable Diffusion Models with Transformers (DiT), ICCV 2023. arXiv:2212.09748
- Chen et al. — PixArt-α, ICLR 2024. arXiv:2310.00426
- Esser et al. — Scaling Rectified Flow Transformers (SD3, MMDiT), ICML 2024. arXiv:2403.03206
Training-free fast samplers
- Lu et al. — DPM-Solver, NeurIPS 2022. arXiv:2206.00927
- Lu et al. — DPM-Solver++, 2022. arXiv:2211.01095
- Zhang & Chen — DEIS, ICLR 2023. arXiv:2204.13902
- Zhao et al. — UniPC, NeurIPS 2023. arXiv:2302.04867
Flow matching, rectified flow, and distillation
- Lipman et al. — Flow Matching for Generative Modeling, ICLR 2023. arXiv:2210.02747
- Liu, Gong, Liu — Flow Straight and Fast: Rectified Flow, ICLR 2023. arXiv:2209.03003
- Salimans & Ho — Progressive Distillation, 2022. arXiv:2202.00512
- Song et al. — Consistency Models, ICML 2023. arXiv:2303.01469
Few-step frontier (2025–2026)
- Lu & Song — Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models (sCM / TrigFlow), ICLR 2025. arXiv:2410.11081
- Zhou, Ermon, Song — Inductive Moment Matching, ICML 2025. arXiv:2503.07565
- Geng et al. — Mean Flows for One-Step Generative Modeling, NeurIPS 2025. arXiv:2505.13447
- Geng et al. — Improved MeanFlow, 2025. arXiv:2512.02012
- Zhang et al. — AlphaFlow, 2025. arXiv:2510.20771
- Frans et al. — One Step Diffusion via Shortcut Models, ICLR 2025. arXiv:2410.12557
- Zhou et al. — Terminal Velocity Matching, ICLR 2026. arXiv:2511.19797
- Deng et al. — Generative Modeling via Drifting, 2026. arXiv:2602.04770